HiveMind Protocol
I. Purpose // Why HiveMind Exists
HiveMind was built to solve a foundational flaw in modern AI systems:
All memory is stored in the cloud.
Enterprises upload their entire knowledge base — documents, logs, communications, even private data — into opaque remote vector databases.
HiveMind rejects this model entirely.
It is a Local-First, Privacy-Preserving Architecture for Agentic RAG, designed so that context stays on your machine, your drive, your control.
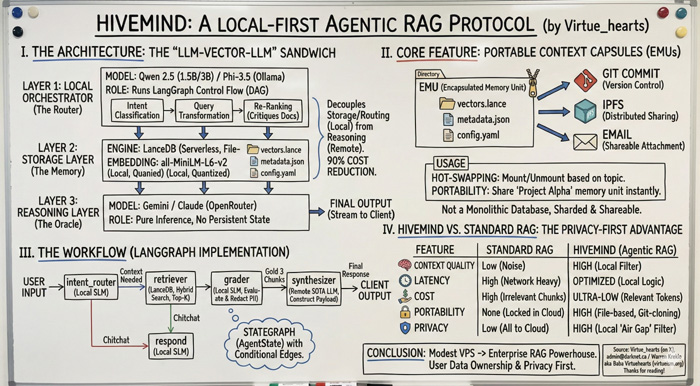
II. EMUs — Encapsulated Memory Units
At the core of HiveMind are EMUs: portable context capsules containing:
• vectors.lance — the local vector index
• metadata.json — semantic map & routing hints
• config.yaml — mount logic + scope rules
EMUs behave like “knowledge containers.” They can be mounted, unmounted, shared, versioned, committed, forked — just like code. No monolithic databases, no cloud ingestion, no data surrender.
III. The Three-Layer HiveMind Stack
Layer 1: SLM Router
Tiny local models (Qwen 2.5, Phi 3, Gemma) classify intent, transform queries, and decide which EMUs to mount.
Cheap, fast, private.
Layer 2: Local Vector Store
LanceDB handles hybrid search (semantic + keyword).
Retrieval happens locally, not in the cloud.
Layer 3: Cloud Oracle
Large models perform pure inference — with zero memory of prior data.
They see only the curated, routed chunks selected locally.
IV. Why HiveMind Is Different
• No monolithic vector databases
• No uploading entire document sets
• No persistent cloud memory
• No vendor lock-in
• Zero data leakage
HiveMind turns RAG into a distributed, air-gapped architecture where:
Only the relevant tokens ever leave your machine.
V. Agentic Workflows
HiveMind integrates with LangGraph, allowing stateful multi-step agents to operate fully locally until the final inference stage. State is stored in EMUs, not in ephemeral cloud sessions.
VI. The Philosophy
HiveMind is a reminder of what the Internet was supposed to be:
• decentralized
• local
• user-owned
• sovereign
AI should not require mass data surrender.
Intelligence should run at the edge.